
Bottlenecks in ProcessFlow execution are the major concern for any integration. They weaken the flow of data and also reduce the overall performance of the application. Some of the bottlenecks are intentional and kept in integration because of constraints, while some are not. As an implementation consultant, the idea of removing bottlenecks is much of a concern. Let us look deep into the types of integration bottlenecks in ProcessFlow execution in this article and try to understand how we can get rid of them.
Here are the two types of bottlenecks
- Intentional or intended bottlenecks
- Unintentional or flawed integration bottlenecks.
To start with, let us consider some of the intentional bottlenecks to which you do not have a solution to.
Connect all your business applications under one single platform to automate the business process and increase your productivity and efficiency!
Intentional or Intended Bottlenecks in ProcessFlow Execution
In case of intentional bottlenecks, we create bottlenecks because of application restrictions. For example, let us suppose the application does not support data to be sent to it beyond a certain point. Here the citizen integrators create or employ bottlenecks intentionally to overcome various scenarios. Here are a few examples of intentional bottlenecks.
Application Restrictions
Some applications restrict the calls to their API based on license. This application wants to be called only sequentially and does not allow either parallel or based on the license of it. For example, SAP Business One DI Server issues a license that restricts the use of API resources based on the number of cores it is licensed. That means if you have a license of 4 cores, you can call 4 API resources at most to the SAP Business One DI Server.
Hence, the implementation consultants, either ask in these cases to upgrade the customer’s license, or else they remove the parallel execution and keep the bottlenecks into the system voluntarily.
API throttling
In the case of Web APIs, SaaS applications also put restrictions to ensure spammers cannot spam an API. API gets throttled automatically whenever a certain amount of calls are reached in a Web API, thereby restricting the next calls to the system.
To handle API throttling, the integration developer sometimes employs certain delays in the process such that it ensures the call is made without reaching the throttle point.
Event APIs
Sometimes the APIs do not directly update the data, rather there is an intermediary API that keeps track of any update of data and gives you back the co-relation id. The co-relation id gives you a separate API URL which you may call to see the status of the update.
Some public APIS where a huge number of calls were made, to overcome scalability of the resources, they keep a queue for any update to back up the API calls. These APIs when the integration developer calls, cannot get the status immediately, and the integration developer needs to wait for the resource update to happen such that they can update the status of the resource.
Unintentional or Flawed Integration in ProcessFlow Execution
Unintentional bottlenecks are the ones that are created automatically because of the logic created in the flows. These bottlenecks are hidden in the context and Citizen Integrators find them tough to overcome. APPSeCONNECT provides various tools to identify these bottlenecks and helps to save precious time and money for our integrators.
Unnecessary Splits on Data
As an implementer, you are required to push data coming from one application to another ensuring no data loss. You are also entitled to optimize the data flow, such that the API calls are minimized and data is sent in correct batches. In APPSeCONNECT, we provide two types of nodes that can help in adjusting the data flow into various nodes. The Splitter allows you to split data into multiple data packets. It gives you an option to split a batch of data into smaller chunks such that it can be easily consumed and sent either sequentially or parallelly. You will also have an option to merge the contents coming from a source into bigger packets to ensure your network latency is minimized.
In the case of APPSeCONNECT, ProcessFlow allows you to split, but let me remind you, a Split gives an overhead of creating a Loop in the pipeline to execute all the packets one by one. Now if you split the content and then you merge them together before pushing the data, that means your APIs are capable enough to consume in Batches, in such a scenario, we should not split the data at all. By optimizing the ProcessFlow, removing Splitter and Merger makes the Process much more readable and performant.
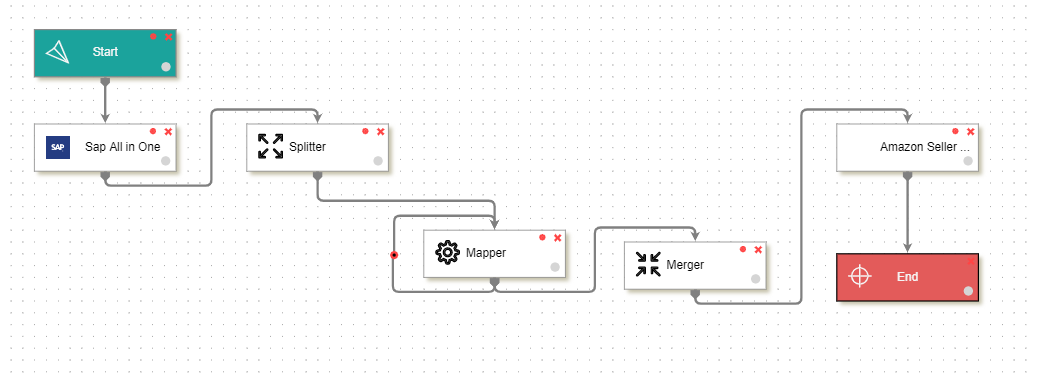
Here you can see this may be a classic example of unnecessary implementation. Here the data coming from SAP is been split into multiple smaller chunks. The mapper then processes each and individual data in a loop. You can see a Self-loop is placed in the Mapper, which will ensure all the data packets are processed in the pipeline. This creates an additional overhead of processing Mapper as many times as the data coming from SAP. And finally, we do a Merge, such that all the mapped items are again merged together into a single file and then sent to the Amazon Seller central.
Sometimes adjusting the amount of data passed through a pipeline can give you more performance, but if you just split and then merge to generate all at a time, it will make this unnecessary. For example, let’s say SAP gets 100 data at a time and you split it into a single packet. The splitter then will generate 100 files, which will be processed one by one using Mapper and finally those 100 mapped files will be merged together into one single file before it is sent to Amazon. In such a case, you can reduce the overhead of calling Mapper again and again, just by removing the Splitter, Merger and self Loop and connecting the Source and Destination nodes with the mapper directly.
Flawed Implementation because of Splits in ProcessFlow
Sometimes using Splitter and merger one can also produce flawed implementation. Let us suppose, you are Splitting in a batch of 7 records. Therefore, when you have 100 records coming from SAP, and you split in a batch of 7 records, you will get 15 packets, 14 packets of 7 records and the 15th packet will hold only 2 records. Now let’s say, you miscalculated the amount of data coming in, and you explicitly mentioned the number of iterations in Self loop as 10. In such a case, the last 5 packets will be lost in transit.
This is a kind of flawed implementation. There will always be a data loss in this scenario, and it is highly recommended to fix these kinds of issues.
How APPSeCONNECT can help in overcoming implementation issues in ProcessFlow
In the case of APPSeCONNECT, any flawed implementation can be easily identified by looking at the Sync Info. The Sync Info window will show the data which are lost as “Unprocessed”. These data are never processed in the pipeline, and hence you can Resync them again to get them posted.
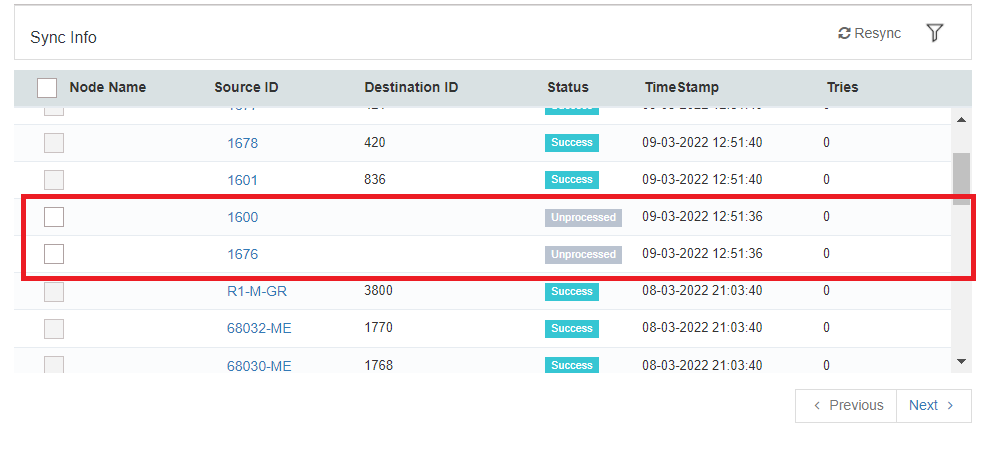
Here you can see the Source IDs for 1600 and 1676 are the ones that are lost from the pipeline because of flawed implementation. You can click on the Source data to open its snapshot. The snapshot gives you a complete overview of where the data is getting lost in the pipeline.

The platform will identify the skipped entries and give you a clue as to why the final data is unprocessed.
In APPSeCONNECT, every data is tracked, and hence from Sync info, you can Re-Run the data again to process it back. If somehow because of flawed implementation a data is unprocessed, you can Resync to sync it back. Our Automatic resync feature is also capable of identifying unprocessed data because of flawed implementation, and would automatically fix it without human intervention.
Conclusion
APPSeCONNECT as a product gives various tools which help in understanding an issue correctly from the platform. Data loss identification is one of the cool features on the platform which as an implementer you would love to use to overcome the burning issue of implementation. This gives the citizen integrators peace of mind, as end-users can also easily go to the product to fix these issues until you fix the issue yourself.
Do let us know your feedback about the feature.
Connect all your business applications under one single platform to automate the business process and increase your productivity and efficiency!




























